Nå har vi passert 10% elbiler på norske veier, og det gikk så fort som de største optimistene våget å håpe. Denne posten er ikke om hvorfor det er viktig og riktig å fortsette, men om hva som skal til. En større satsning ladeinfrastruktur må til. Regjeringen har lagt opp til at markedet skal fikse, men det ser ikke ut til at det går fort nok. Jeg tror det rett og slett er for komplisert, mange av aktørene er for små til å ta så kompliserte ting, og i den grad man har store aktører, så kan vi risikere å få for lav konkurranse, og derfor dårlige tilbud. Vi trenger en politikk som både sikrer rask utbygging og konkurranse mellom forskjellige aktører.
Jeg er redd for at vi havner i samme situasjon som i “den store telefonkatastrofen”: så sent som i 1979 stod 100000 nordmenn på venteliste for å få telefon, teknologiutviklingen gikk for fort, men det offentlige lå bakpå og klarte ikke automatiseringen av telefonsentralene. Øystein Sunde lagde en sang om det i 1976…
Lading på forskjellig skala
Hjemmelading
Hjemmelading er den aller viktigste ladeformen. At bilen kan lades der den uansett står om natta. Det gjør at man alltid starter med full rekkevidde, og det gjør at elbilen er bedre enn flytende drivstoff, når man først har hatt elbil en stund, så er det å kjøre innom en bensinstasjon i dagliglivet en belastning. For oss i enebolig er saken klar, vi må kjøpe en ladestasjon.
For borettslag er saken en annen, fordi det kan bli store investeringer for borettslaget å få det til fordi infrastrukturen ganske sikkert ikke er dimensjonert for belastningen. Oslo har hatt en god støtteeordning en stund som man har sett på for hele landet. Man burde bare få det gjort.
Destinasjonsladerne
Dette er også små ladeanlegg på steder der folk er en dog stund, gjerne natta over. Mange biler vil etterhvert få 22 kW ombordladere (slik Renault Zoe har hatt siden starten). Det bør være standardutstyr at det er slike ladere tilgjengelig for besøkere på steder som ligger litt for seg selv, som dyreparker, fornøylsesparker, høyfjellshoteller, osv. Dette er spesielt hjelpsomt siden ingen kan forvente at det er tilstrekkelig mange ladere tilgjengelig på de store utfartsdagene, som påske, pinse, osv. Da må folk ha hatt mulighet til å lade opp i løpet av tiden på tur.
Siden campingvogn fort dobler energiforbruket, er det også viktig at sånne kommer opp på campingplasser, det er for meg personlig det tekniske problemet står mellom meg å gå fullelektrisk (men det viktigste er økonomisk, vi har ikke råd til en stor nok bil, det er bare Tesla Model X som er stor nok for hele familien).
Mange steder vil enkelt kunne få montert sånne, og de koster under 10000 kroner, så en enkel støtteordning burde få fart på løsningen her. Med den konklusjonen, la oss gå til de aller største:
Lega-parkene
Jeg kaller dem lega-parker, de som kommer til å bli landets største ladeparker. “Lega” fordi jeg tipper de kommer til å trekke 50 megawatt effekt, og L er 50 i romertall, L og mega blir lega. Jeg tror at vi i framtiden vil tenke på et ladestopp som tid vi ønsker å fylle med noe, ikke tid vi ønsker å slå ihjel. Noen steder i landet ser jeg derfor for meg ladeparker med kapasitet på mer enn 100 biler samtidig, som står der en snau time. Folk ønsker å fylle denne tiden med god mat eller spennende aktiviteter eller kulturtilbud, eller bare få gjort noen ærender. Det gir rike muligheter for lokalt næringsliv rundt disse ladeparkene. Hvis man har noen spesielt store ladeparker, vil det være større sannsynlighet for gjennomstrømning og derfor mindre kø enn hvis det er mer fragmentert.
Problemet er at 50 MW er ganske høy effekt. Det er som “kraftkrevende industri”. Man kan ikke ta ut så mye av distribusjonnettet, de kraftlinjene som går rundt til husene våre. Faktisk vil det være en ganske mye også på regionalnettet. Det er effekttoppene man må dimensjonere etter, og dermed bestemmer det hvor mye kraft man må ha tilgjengelig, og hvor store naturinngrep man må gjøre for kraftlinjer. Dette må betales for, og derfor er effektprising fornuftig, fordi det er en betaling for å minimere skadevirkningene.
Men samtidig må det ikke underminere den ladeinfrastrukturen vi trenger så sårt for å kunne opprettholde veksten i elbiler. Så, kan man tenke seg at det er mulig å legge ladeparkene ved elektrisk infrastruktur slik at man minimerer behovet for slike potensielt skadelige investeringer?
Jeg har en tendens til å falle i staver over kart, og det ble fort klart at svaret på det spørsmålet synes å være ja. Vi kan plassere ladeparkene der det allerede er høy effekt tilgjengelig. NVE har nemlig publisert et fint atlas over strømnettet. Samtidig har Vegvesenet fine kart der man kan få ut trafikkdata. Med dette har jeg sett meg ut følgende kommuner:
- Vinje,
- Gol,
- Vaksdal,
- Nord-Aurdal,
- Nord-Fron,
- Eidsvoll,
- Tønsberg,
- Vestby.
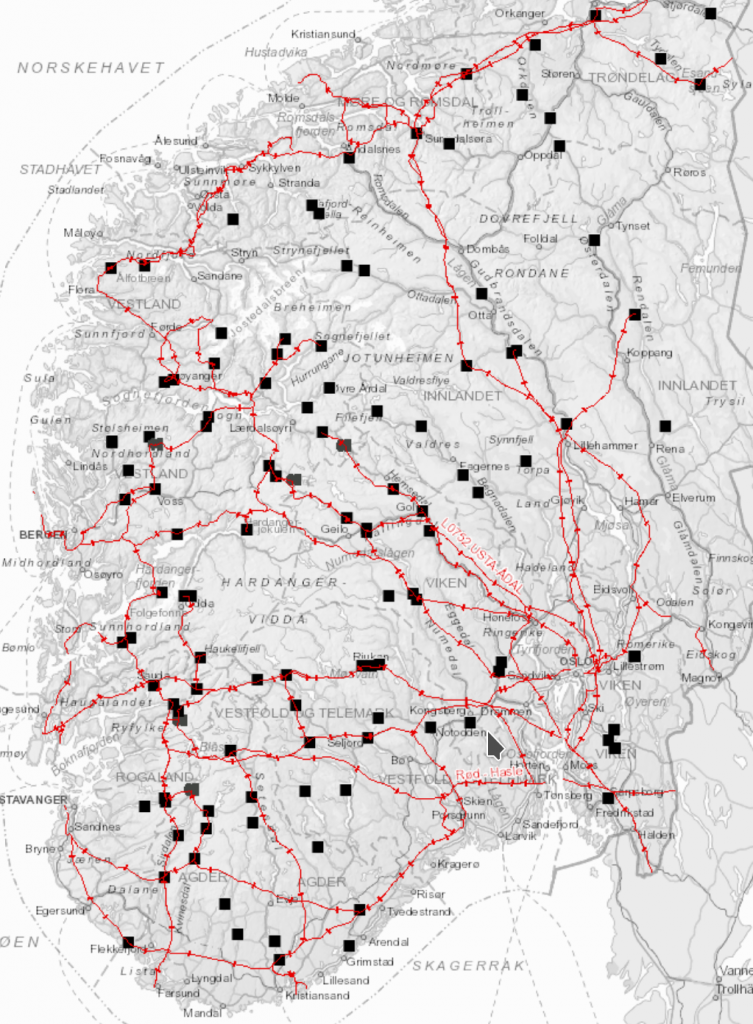
Det jeg ser med disse er at det enten er regulerbar kapasitet i umiddelbar nærhet til gunstige steder typisk midt mellom store befolkningssentra (som Gol og Vinstra) eller fordi det finnes trafostasjoner på sentralnettet rett ved hovedfartsårer (som Barkåker i Tønsberg kommune eller Tegneby i Vestby). Jeg tenker at hvis man kan trekke kabel rett fra disse knutepunktene, fordi de ligger nær ladeparkene, vil de i veldig liten grad belaste regionalnettet og distribusjonsnettet. Da bør man kunne lage egne ordninger for å prise effekten disse få stedene tar ut. Med andre ord, ingen nettleie hvis man ikke bruker nettet.
Jeg tenker meg tre tiltak:
- Det bør være en nasjonal fagmyndighet, f.eks. NVE, som har det overordnede faglige ansvaret, og som koordinerer kraftselskaper, netteiere og kommunene.
- Et statlig eller flere kommunale operatørselskaper som har ansvaret for utbygging og framføring av kapasitet, salg av kapasitet sørge for konkurranse mellom ladeoperatører (som Ionity, Fortum, Grønn Kontakt, Tesla, etc), osv. Jeg tror det må være offentlig drevet i starten, markedet har ikke klart det hittil, men at det kan privatiseres etterhvert når det er vel etablert. Statkraft kunne i prinsippet ha en slik funksjon, men da måtte de selge seg ut av Grønn Kontakt igjen.
- Bevilgninger til en nevnte pilotkommuner slik at de kan ha folk i som kan støtte utbyggere både til å utvikle tomter, koordinere mellom forskjellige utbyggere, tiltrekke seg annen næringsvirksomhet (restauranter, etc), samt koordinere med sentrale myndigheter, operatørselskaper og fagetater som nevnt over.
Vinje, Gol og Nord-Fron er valgt fordi de huser noen landets største regulerbare kraftressurser, samtidig som hovedfartsårer går gjennom dem og er såpass langt fra de større byene at de sannsynligvis vil se stort behov for lading. Vaksdal har store regulerbare energiressurser og ligger både langs hovedfartsåre og ikke langt fra Bergen.
Nord-Aurdal er valgt fordi de også har betydlige kraftressurser, litt dårligere nett, og også mye langdistansetrafikk.
Eidsvoll, Tønsberg og Vestby er valgt fordi noen av de største kraftkablene på sentralnettet går igjennom og også huser kraftige transformatorstasjoner, samtidig som de ser mye av trafikken i Østlandsområdet. Eidsvoll har forøvrig allerede en av Europas største ladeparker, men den har ikke kabler som tillater den å vokse særlig.
De mellomstore
I tillegg til de største vil det være behov for en del mellomstore, med noen MW effekt. Brokelandsheia er egentlig et godt eksempel på et sted som allerede har en del tilbud for dem som vil stoppe en time, men de har ikke så store kraftressurser. Et eksempel på et sted som har det er Alvdal, som har mye tungtrafikk, selv om de har lav total trafikkmengde. Det er interessant også fordi Aukrust-senteret er et godt eksempel på et kulturtilbud som kan få et solid oppsving ved en ladepark i nærheten.
Jeg ser også behov for noe på Sørvest-landet, men der er det litt mer uklart akkurat hvor det bør være. I nord er det en del mindre trafikk, og det er derfor mindre trolig man kommer opp i de veldig høye effektene man ser andre steder, dessuten er det aldri veldig langt til sentralnettet. Rana har jo også enormt med kraft. Verdal og Lundamo kan også være aktuelle inn mot Trondheim, mens Skei og Aksdal kan være aktuelle steder på E39.
Riksveinettet
Forøvrig på riksveinettet trenges det også noen lynladere, det er en del områder som ikke dekkes godt av de store ladeparkene som over, f.eks. Strynefjellet. Det er også noen lange fylkesveier, som Fv 17 og Fv 40, med liknende behov. Men her kan det forventes at man trenger godt under 10 MW, og det er derfor langt enklere å koble på. Det er mulig at incentivordningene bør være de samme for å sørge for at de legges ved eksisterende infrastruktur, og nøytrale operatørselskaper er muligens også ønskelig, men rent teknisk er dette enklere.
Hva med Oslo?
Folk flest bor i Oslo, og det er kanskje naturlig med ladeparker der? Jeg tror at små destinasjonsladere er mye viktigere, at man kan lade på lav effekt på det stedet man skal.
Likevel tittet jeg litt på noen steder der det kanskje vil gi mening å ha ladeparker med noen MW. Jeg så etter følgende:
- Nær transformatorer på sentral- eller regionalnettet
- Utenfor bykjernen
- Nær T-banen, så folk kan lade mens de gjør raske ærender i Oslo sentrum
- Nær andre servicetilbud
- Nær hovedveier.
Jeg fant tre steder:
Økern virker aller best egnet, på Trostrud må man kjøpe opp eksisterende bebyggelse og bygge gangveier, og på Montebello er det et stykke ned til Ring 3.
Hvor fort kan det gå?
Har vi ikke litt tid, i den forstand at selv om man kanskje ser at alle nye biler som selges i 2025 er elektriske, så tar det lang tid før det er veldig mange? La oss ta en langt mer naiv framskrivingsmodell, basert på globale salg. Ifølge den ble det solgt 201 000 elbiler på verdensbasis i 2017, 397 000 i 2018, jeg har ikke sett fjorårets tall ennå, men det har kanskje passert en million. Norsk elbilpolitikk har utvilsomt en del av æren for dette. Dette har vært og er politikk som fungerer.
Vi ser igjen i disse tallene slik teknologi vanligvis blir introdusert i markedet: Den skjer ikke jevnt, men går sakte i starten, inntil vi ser et mønster der vi ser en dobling med en viss tidsperiode. De tre siste årene har vi altså sett en dobling hvert år. Kanskje det går fortere. Det betyr at hvis det ble 1 million elbiler globalt i 2019, er den normale utviklingen at det blir solgt 2 millioner neste år, så 4 mill i 2021, 8 mill i 2022, 16 mill i 2023, 32 mill i 2024, 64 mill i 2025, 128 millioner i 2026.
128 millioner elbiler solgt globalt i 2026. Det er hele verdensmarkedet for nye biler, allerede i 2026. Ikke verst, hva?
Så, kanskje det kan gå så fort? Eller kanskje ikke, men la oss planlegge for en rask utskifting. Hvis folk faktisk får lademuligheter ser jeg for meg at vi får en betydelig bensinstasjondød, og det igjen vil føre til at det er enda mer plunder og heft assosiert med bensin, og det vil gjøre at gamle fossiler blir omtrent umulig å selge. Det blir også en utfordring som må løses.
